Monitor Event Log Virtuozzo Storage
Để monitor cluster trên Virtuozzo Storage có thể dùng lệnh “pstorage top” hoặc để xuất event log có thể dùng “pstorage get-event”.
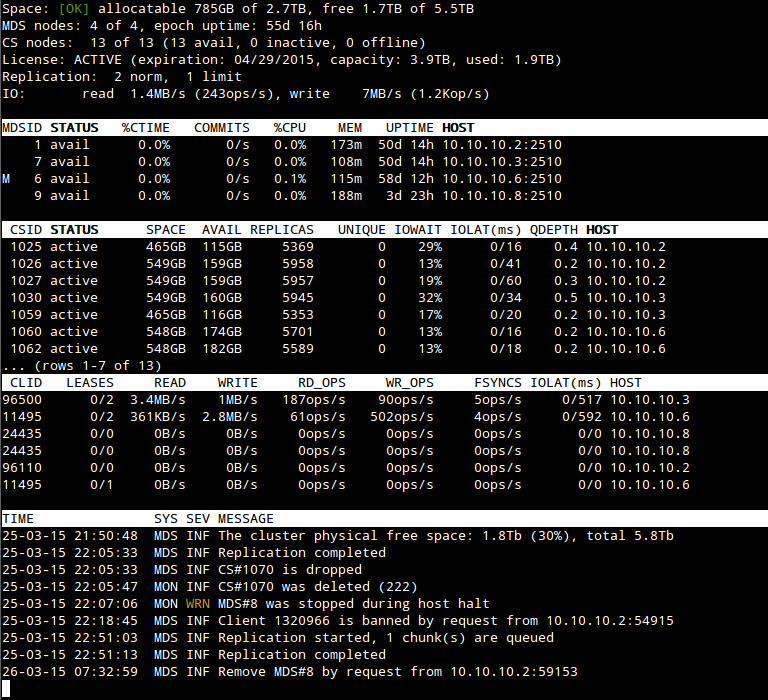
Một số thông tin của event log:
| Column | Description |
|---|---|
| TIME | Thời gian xảy ra sự kiện |
| SYS | Thành phần nào của cluster có sự kiện ( ví dụ “MDS” cho mds server) |
| SEV | Mức độ của sự kiện |
| MESSAGE | Tin nhắn mô tả sự kiện |
Dưới đây là một số event log cơ bản, thường xuyên xuất hiện khi sử dụng lệnh “pstorage top”:
| Event | Severity | Description |
|
MDS#N (addr:port) lags behind for more than 1000 rounds |
JRN err |
Được tạo ra bởi MDS Master khi phát hiện 1 MDS#N đang ở trạng thái stale |
| MDS#N (addr:port) didn’t accept commits for M sec |
JRN err |
MDS#N không kết nối đến cluster sau M giây. Thông báo này chỉ có thể xảy khi dịch vụ MDS có vấn đề, cần phải xử lý càng sớm càng tốt |
| MDS#N (addr:port) state is outdated and will do a full resync |
JRN err |
Vấn đề có thể do MDS#N kết nối đến MDS master qúa chậm hoặc mất kết nối trong thời gian dài điều đó có thể dẫn đến MDS#N không thực sự quản lý trạng thái của metadata và cần phải đồng bộ hóa lại. |
|
The cluster is degraded with N active, M inactive, K offline CS |
MDS warn | Thông báo này thể hiện có một số chunk đang ở trạng thái: Inactive: Không gửi bất kỳ tin nhắn đăng ký nào tới MDS. Offline: CS ở trạng thái inactive lớn hơn mds.wd.offline_tout = 300000 ms |
| The cluster failed with N active, M inactive, K offline CS (mds.wd.max_offline_cs=n) | MDS err | Thông điệp xuất hiện khi số chunk ở trạng thái offline vượt qúa mds.wd.max_offline_cs (mặc định là 2). Khi cluster failed thì cơ chế replicas tự động sẽ không còn hoạt động, người quản trị cluster cần phải khắc phục lỗi cho các chunk bị lỗi hoặc điều chỉnh lại tham số mds.wd.max_offline_cs. Thiết lập giá trị 0 để vô hiệu hóa cơ chế “failed mode completely” |
| The cluster is filled up to N% |
MDS info/warn |
Thể hiện dung lượng hiện đang sử dụng của cluster. Tin nhắn này xuất hiện khi sử dụng dung lượng của cluster lớn hơn hoặc bằng 80%. Điều này khá quan trọng, cần phải đảm bảo lượng storage cho sự replicas khi 1 chunk server bị lỗi hoặc cho các data mới được đưa vào |
| CS#N has reported hard error on ‘path’ | MDS warn | Xảy ra khi CS#N phát hiện được ổ đĩa có dấu hiệu bị hư hỏng. Khuyến cáo người quản trị cluster cần phải thay thế ổ disk bị hư hoặc kiểm tra lại phần cứng càng sớm càng tốt. |
| Failed to allocate N replicas for ‘path’ by request from <addr:port> – K out of M chunks servers are available | MDS warn | Cluster không thể cấp phát các bản sao của chunk, có thể xảy ra khi chunk bị out of disk space. |
| Failed to allocate N replicas for ‘path’ by request from <addr:port> since only K chunk servers are registered |
MDS warn |
Cluster không thể cấp phát các bản sao chunk. Bởi vì không có đủ số chunk đăng ký trên cluster. |
Troubleshooting “Out of Disk Space”:
Khi bị trình trạng không gian lưu trữ của cluster bị chiếm dụng qúa nhiều, cần phải nâng cấp thêm chunk hoặc xóa bỏ các dữ liệu không cần thiết. Điều này xảy ra khi dung lượng cluster bị chiếm dụng qúa 95%, sự phân bổ dữ liệu mới của các chunk sẽ không còn được đáp ứng cho đến khi cluster có thể đáp ứng được nhu cầu. Để đảm bảo an toàn dữ liệu, I/O của người dùng sẽ bị khóa và có thể dẫn đến các Container và Virtual Machine bị đóng băng. Khuyến cáo các admin cluster nên giữ dung lượng của cluster trên 10% để đề phòng trường hợp node hoặc một số chunk bị lỗi.
Dấu hiệu:
1. I/O của điểm kết nối từ client đến cluster có bị nghẽn, “desmg” báo cáo về nghẽn I/O, các CT hoặc VM có thể bị đóng băng
2. “pstorage top” hoặc “pstorage get-event” thông báo lỗi tương tự như “Failed to allocate X replicas at tier Y since only Z chunk servers are available for allocation”.
Giải pháp:
1. Giải phóng dung lượng ổ đĩa bằng xóa các dữ liệu không cần thiết.
2. Thêm mới các chunk server với các ổ đĩa trống.
3. Nếu các giải pháp trên vẫn chưa cải thiện được:
– Điều chỉnh lại tham số replicas (chẳng hạn 2:1)
– Giảm sự phân bổ dữ trữ, ví dụ thực hiện trên cluster “odscloud”:
# pstorage -c odscloud set-config mds.alloc.fill_margin=2
Mặc định giá trị mds.alloc.fill_margin bằng 5. Khuyến cáo sau khi khôi phục lại dung lượng cluster, trả giá trị mds.alloc.fill_margin=5.
Doanh nghiệp quan tâm về giải pháp Tổng đài ảo vui lòng liên hệ trực tiếp cho ODS theo số hotline (028) 7300 7788 hoặc website: https://ods.vn để được tư vấn và hỗ trợ nhanh nhất.

